
前言
书接上回,虽然小编都不敢轻易在这里吹牛逼,但是该优化升级还是很有必要的,不然作为技术负责人或者架狗屎的话岂不是百无一用了。
虽然大部分公司不会分表,但不少公司应该会做一个备份库,一般通过MySql自带的主从复制功能来实现(如果没做,就当我没说)。所以,在实际开发中,我们可以在分表的的基础上进行读写分离,来减缓数据库压力。
技术选型
仅供参考:SpringBoot 2.2.6.RELEASE + shardingsphere 4.0.1 + MySQL + Druid + lombok + JPA
撸主这里选的是JPA,无它,习惯而已。不少小伙伴喜欢使用MyBatis,后期有时间会单独拉一个分支。
主从复制
读写分离的前提是主从复制,这个需要在MySql实例间自行配置,必须是两个单独的实例。顾名思义,主从复制允许将来自一个MySQL数据库主服务器的数据复制到一个或多个MySQL数据库从服务器。
优势:
横向扩展解决方案,在多个从站之间分配负载以提高性能。所有写入和更新都在主服务器上进行。但是,读取可以在一个或多个从实例上进行。
数据安全性,数据被同步到从站,并且从站可以暂停复制过程,所以可以在从站上运行备份服务而不会破坏相应的主数据。
配置案例
为了测试方便,这里使用了一个实例上的两个不同的库,生产环境需要自行配置主从同步。
server.port=8080
spring.jpa.database=mysql
spring.jpa.hibernate.ddl-auto=update
spring.jpa.show-sql=true
spring.main.allow-bean-definition-overriding=true
spring.shardingsphere.datasource.names=master,slave
# 主库
spring.shardingsphere.datasource.master.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.master.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.master.url=jdbc:mysql://localhost:3306/shardingsphere0?serverTimezone=UTC&useSSL=false
spring.shardingsphere.datasource.master.username=root
spring.shardingsphere.datasource.master.password=root
# 从库
spring.shardingsphere.datasource.slave.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.slave.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.slave.url=jdbc:mysql://localhost:3306/shardingsphere1?serverTimezone=UTC&useSSL=false
spring.shardingsphere.datasource.slave.username=root
spring.shardingsphere.datasource.slave.password=root
spring.shardingsphere.masterslave.load-balance-algorithm-type=round_robin
spring.shardingsphere.masterslave.name=ms
spring.shardingsphere.masterslave.master-data-source-name=master
spring.shardingsphere.masterslave.slave-data-source-names=slave
#是否开启SQL显示,默认值: false
spring.shardingsphere.props.sql.show=true
#工作线程数量,默认值: CPU核数
spring.shardingsphere.props.executor.size=4
#是否在启动时检查分表元数据一致性,默认值: false
spring.shardingsphere.props.check.table.metadata.enabled= false最后,分别测试一下读写,如果分别操作了两个库,说明配置成功。
@Api(tags ="订单管理")
@RestController
@RequestMapping("/order")
public class OrderControl {
@Autowired
private OrderRepository orderRepository;
/**
* 插入
*/
@PostMapping("/save")
public void save(){
for(int i=0;i<10;i++){
OrderEntity entity = new OrderEntity();
entity.setUserId(i);
entity.setGoodsId(1000L);
entity.setPayStatus((short)0);
orderRepository.save(entity);
}
}
/**
* 列表
*/
@PostMapping("/list")
public Result list(){
List<OrderEntity> list = orderRepository.findAll();
return Result.ok(list);
}
}小结
以上仅仅是一个小小的案例,但是这种案例大部分公司可能都会有用到。撸主之前都是手动自己撸AOP实现读写分离,如今通过 shardingsphere 简单配置即可实现,不可谓不香!
推荐
一款从0到1构建分布式秒杀系统,脱离案例讲架构都是耍流氓。
码址:gitee.com/52itstyle/spring-boot-seckill
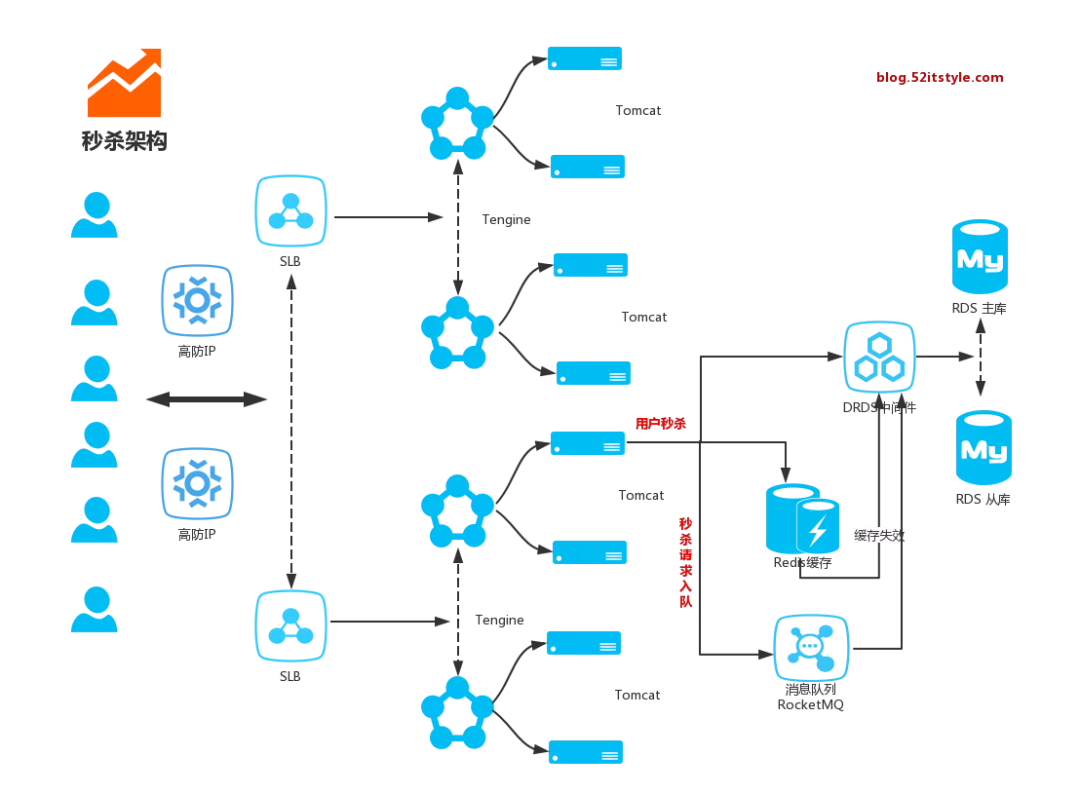
源码案例
https://gitee.com/52itstyle/spring-boot-sharding-sphere

